Daily Trend [10-18]
【1】4D Gaussian Splatting for Real-Time Dynamic Scene Rendering
【URL】http://arxiv.org/abs/2310.08528
【Time】2023-10-12
一、研究领域
动态场景,实时渲染
二、研究动机
高分辨率的实时动态场景渲染,并且保证高效率的训练和存储
三、方法与技术
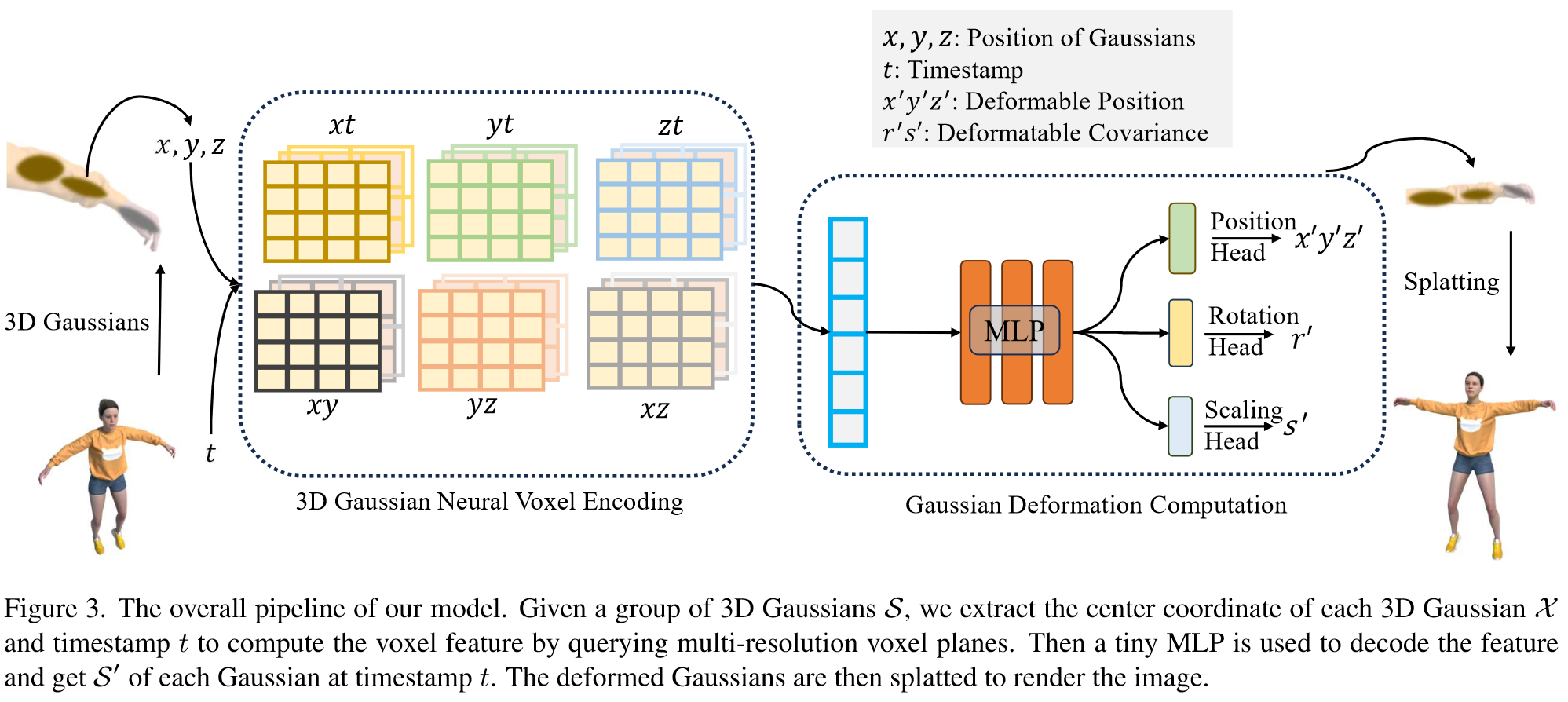
(1)3D 高斯神经体素编码:使用多分辨率HexPlane voxel module来编码每个3D Gaussian的空间和时间信息,因为附近的高斯总是共享相似的变形,而远处的高斯分布之间的关系也不容忽视
(2)高斯变形计算:用一个紧凑的decoder layer和独立的MLP计算位移、旋转、缩放
(3)Optimization:静态初始化+变形联合优化(微调)
四、总结
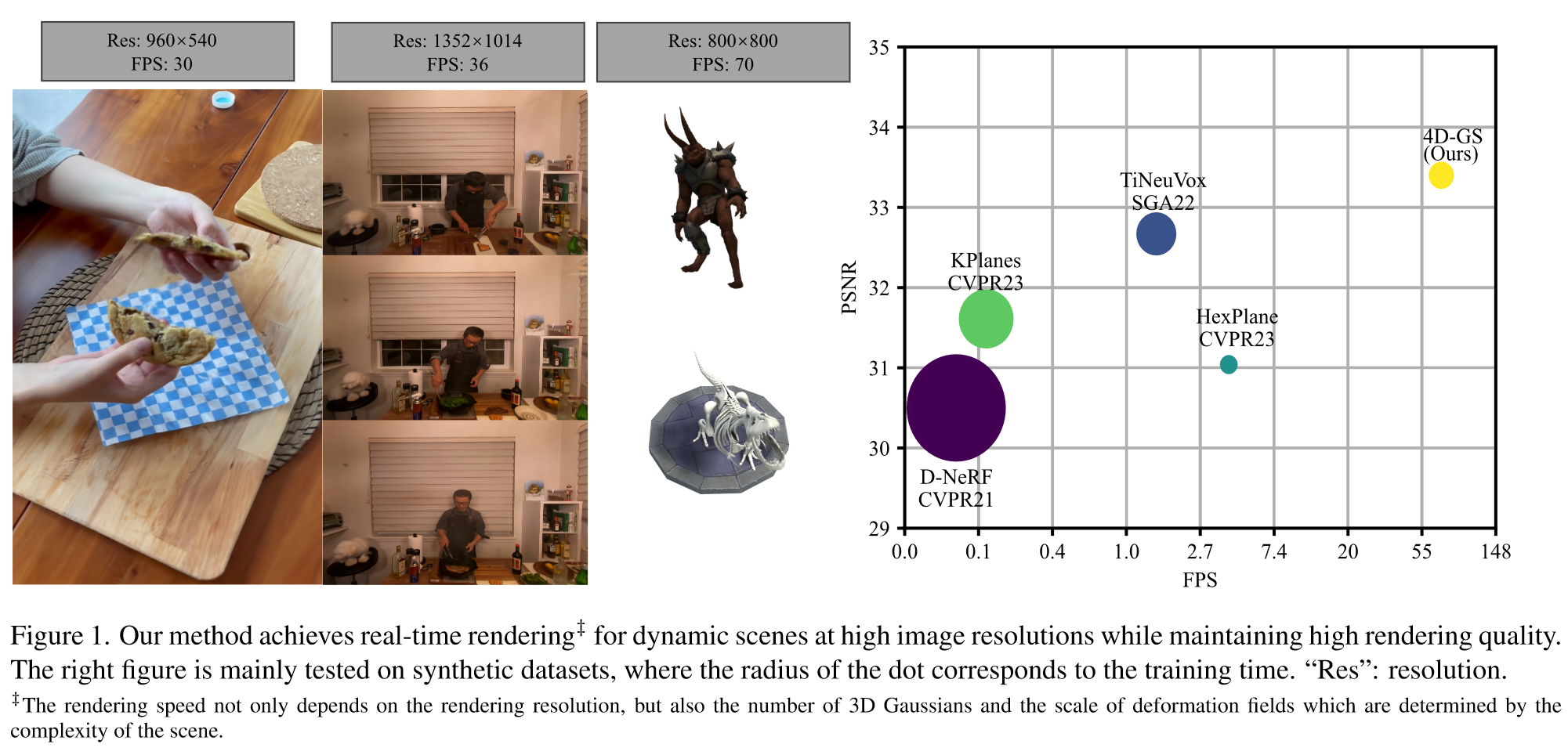
直接看图,性能非常恐怖:
五、推荐相关阅读
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
【2】From CLIP to DINO: Visual Encoders Shout in Multi-modal Large Language Models
【URL】http://arxiv.org/abs/2310.08825
【Time】2023-10-12
一、研究领域
视觉编码器,MLLM(多模态大语言模型)
二、研究动机
研究 MLLM 的不同视觉编码器的有效性,由此建议更好的特征/策略来提高MLLM的visual能力
三、方法与技术
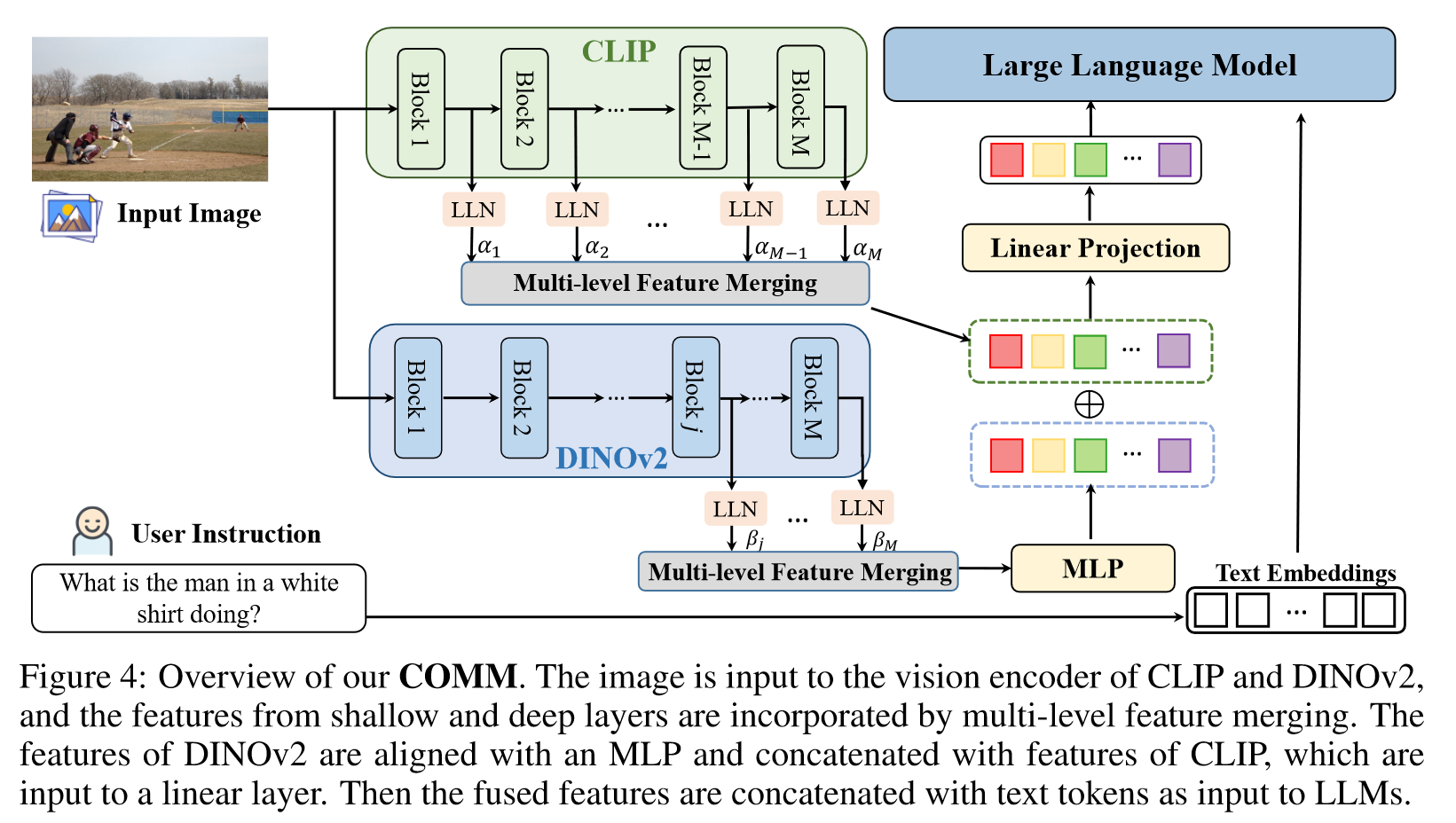
经过实验发现CLIP的浅层REC分高,深层POPE分高,DINOv2的深层REC分高,但是浅层特征缺乏语义信息,所以propose了一种混合特征COMM:提取CLIP的所有层特征和DINOv2的深层特征多级融合,作为LLM的输入。可以带来显著的性能提升。
四、总结
实验比较完整,结论直观上可作为经验参考
【3】Mastering Diverse Domains through World Models
【URL】http://arxiv.org/abs/2301.04104
【Time】2023-01-10
一、研究领域
World Model,RL,MineCraft
二、研究动机
希望创建一种无需调整即可学习掌握新领域的通用算法,从而克服专家知识的障碍,并将强化学习扩展到广泛的实际应用。
三、方法与技术
(1)Symlog Predictions:一种适合平稳学习和跨领域的变换策略。DreamerV3 在解码器、奖励预测器和批评器均中使用Symlog Predictions
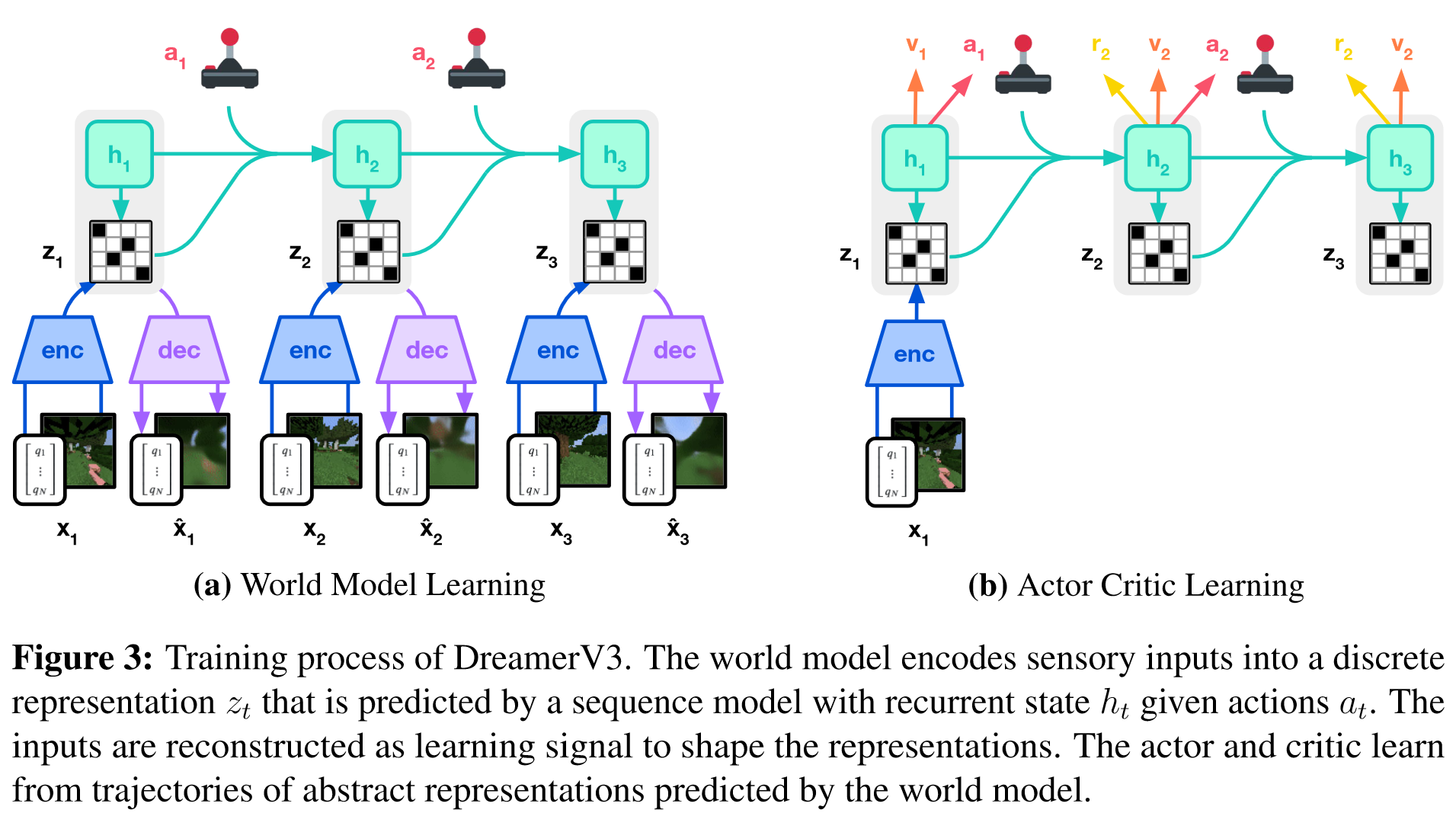
(2)World Model Learning:世界模型通过自动编码学习感官输入的紧凑表示,并通过预测未来的表示和潜在行动的奖励来实现规划,具体实现为RSSM,使用KL损失
(3)Actor Critic Learning:actor和critic神经网络纯粹从世界模型预测的抽象序列中学习行为。在环境交互过程中,通过从参与者网络中采样来选择动作,而无需前瞻规划。
四、总结
DreamerV3 是第一个在 Minecraft 中从头开始收集钻石的算法,而无需人类数据或课程。实现细节看不太懂,但是感觉特牛逼。
【4】Neural Volumetric Memory for Visual Locomotion Control
【URL】http://arxiv.org/abs/2304.01201
【Time】2023-04-03
一、研究领域
3D重建,3D感知,Robotic Control
二、研究动机
将3D感知纳入强化学习pipeline中,以得到集成视觉的运动控制器,因此引入用于决策的短期记忆机制(而不关注视图合成)
三、方法与技术
提出了神经体积记忆(NVM)——一种场景特征的 3D 表示格式。它将一系列视觉观察结果作为输入,并输出代表周围 3D 结构的单个 3D 特征体积。
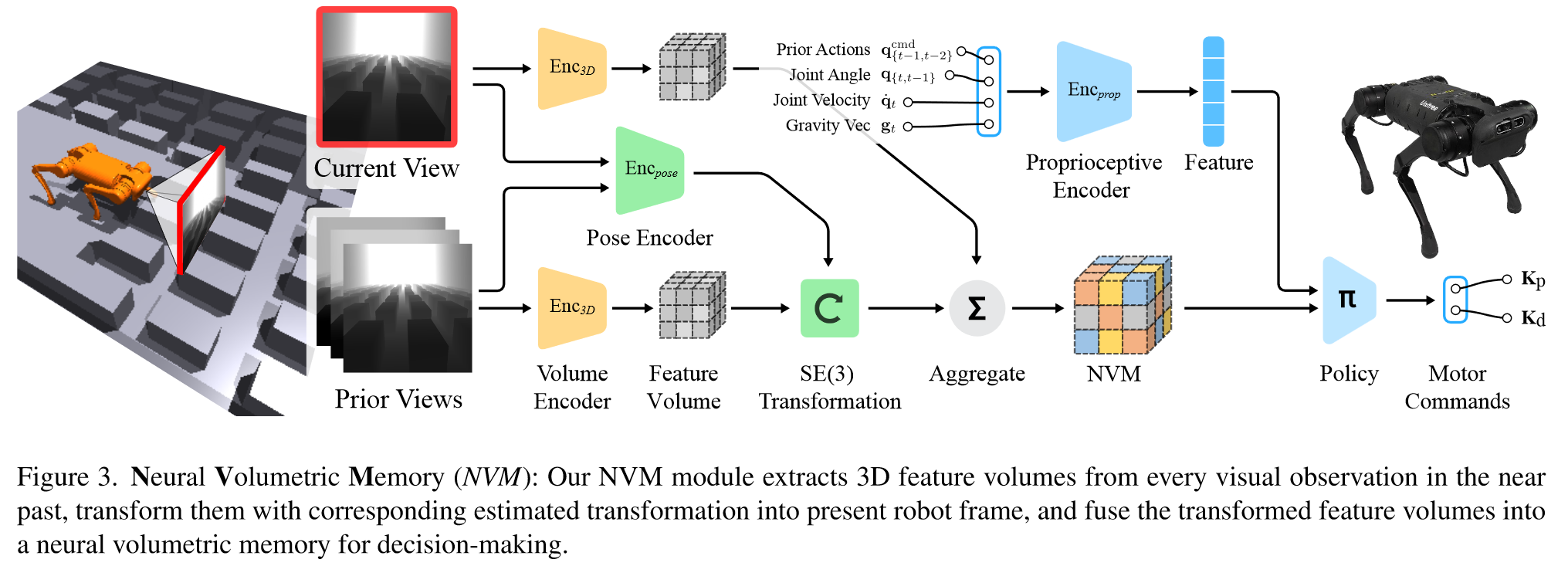
(1)3D Encoder 和 Pose Encoder:从 2D 图像提取 3D 特征和估计帧间变换
(2)Learning NVM via Self-Supervision:Decoder 将 3D 特征映射到 2D 图像,使用 L1 损失自监督训练 3D Encoder 和 Pose Encoder,目的是促进周围 3D 结构和相机姿势之间的解开
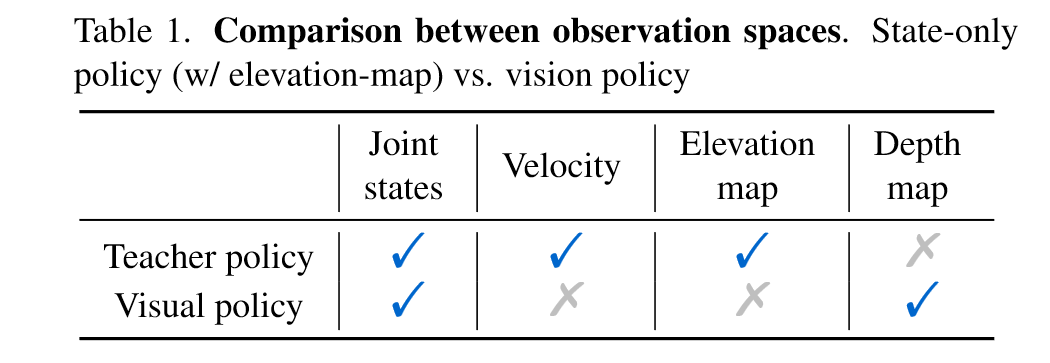
(3)Teacher Policy and Visuomotor Distillation:前者基于state-only policy,后者基于vision policy,这样做的目的是加速训练,并且通过行为克隆来训练视觉策略:
四、总结
NVM为机器人执行决策提供了可靠的周围 3D 结构信息,从而帮助其利用 visual observation
【5】TokenFlow: Consistent Diffusion Features for Consistent Video Editing
【URL】http://arxiv.org/abs/2307.10373
【Time】2023-07-23
一、研究领域
视频编辑,扩散模型
二、研究动机
生成遵循输入文本提示(编辑目标)的高质量视频,同时保留原始视频的空间布局和运动。
三、方法与技术
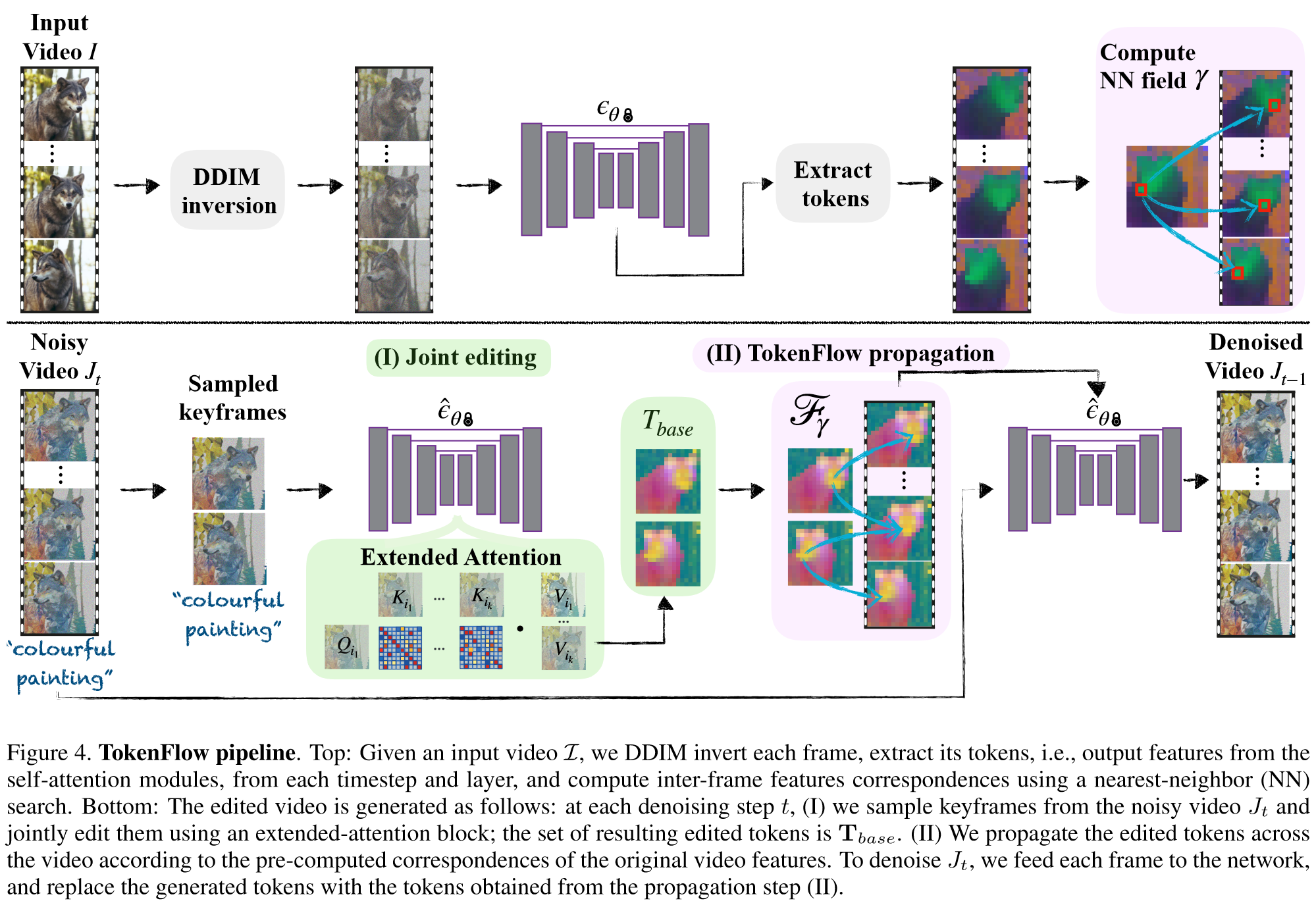
(1)Pre-processing:对每一帧执行inversion,然后提取self-attention module每层的特征token
(2)Keyframe Sampling and Joint Editing:随机采样一组关键帧,每个关键帧都查询所有其他关键帧,并从中聚合信息,从而使编辑帧中的appearance大致统一
(3)Edit Propagation via TokenFlow:将关键帧的特征传播到其它帧(整个视频)
四、总结
从DEMO来看,视频编辑的一致性提高了很多